Motus is a unified latent action world model that leverages existing pretrained models and rich, sharable motion information. Motus introduces a Mixture-of-Transformers (MoT) architecture to integrate three experts (understanding, action, and video generation) and adopts a UniDiffuser-style scheduler to enable flexible switching between different modeling modes (World Models, Vision-Language-Action Models, Inverse Dynamics Models, Video Generation Models, and Video-Action Joint Prediction Models). Motus further leverages optical flow to learn latent actions and adopts a three-phase training pipeline and six-layer data pyramid, thereby extracting pixel-level "delta action" and enabling large-scale action pretraining.
Motus: A Unified Latent Action World Model
1Tsinghua University
2Shengshu
3Peking University
4Horizon Robotics
*Joint first authors †Joint project lead
*Joint first authors †Joint project lead
Framework Overview
Motus Architecture
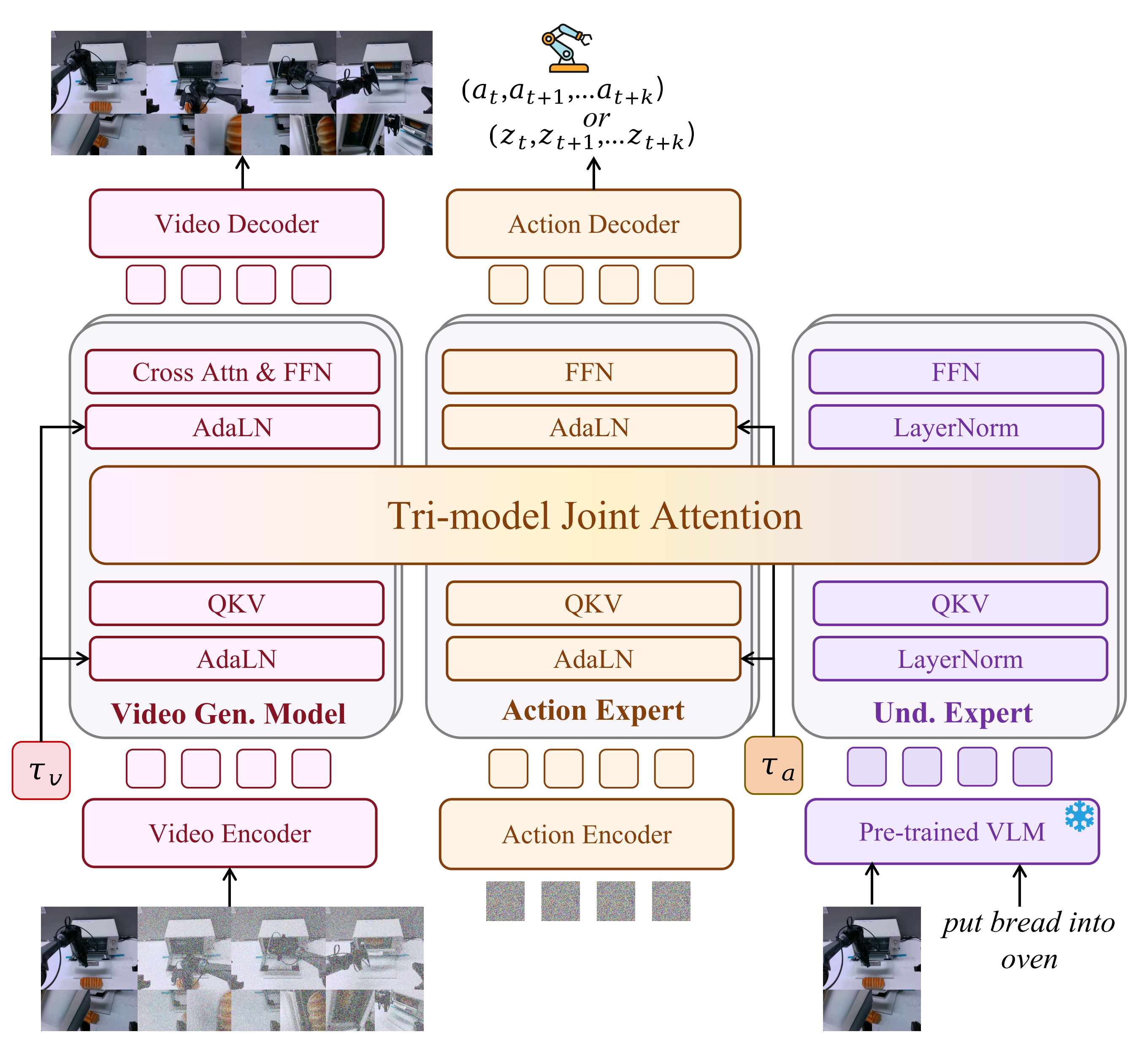
Figure 1: Motus Architecture. Here, $a_t \dots a_{t+k}$ are actions, $z_t \dots z_{t+k}$ are latent actions, and $\tau_v$ and $\tau_a$ are the rectified flow timesteps for the video generation model and the action expert, respectively.
Latent Actions
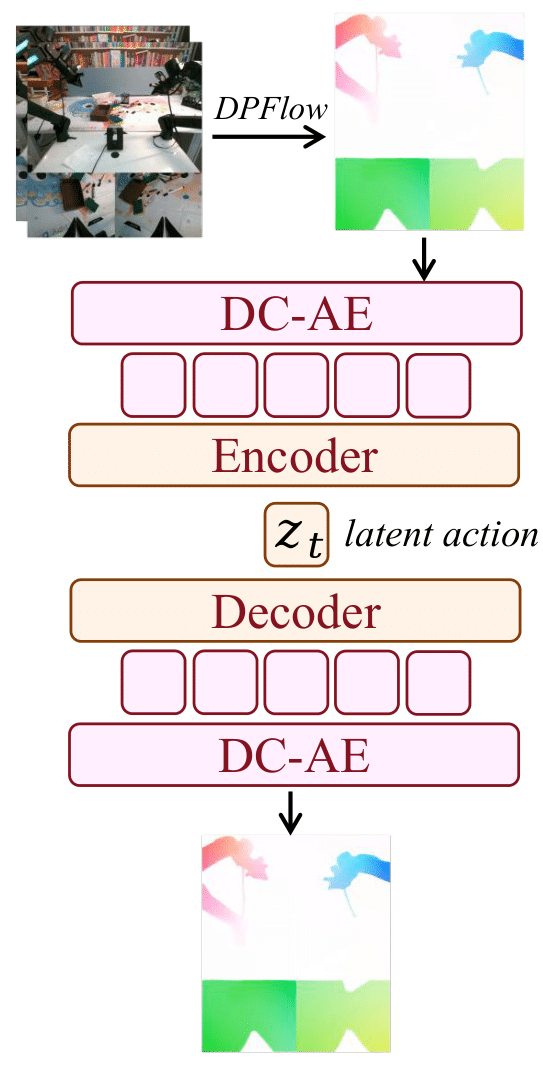
Figure 2: The Latent Action VAE. Optical flow-based representation that bridges visual dynamics with control signals through a variational autoencoder architecture.
To leverage large-scale heterogeneous data, we introduce latent actions that encode motion directly from optical flow. DPFlow computes pixel-level displacements between frames, which are then compressed via a deep convolutional variational autoencoder (DC-AE) and a lightweight encoder, enabling the model to learn cross-embodiment motion priors from diverse video sources.
Data Pyramid
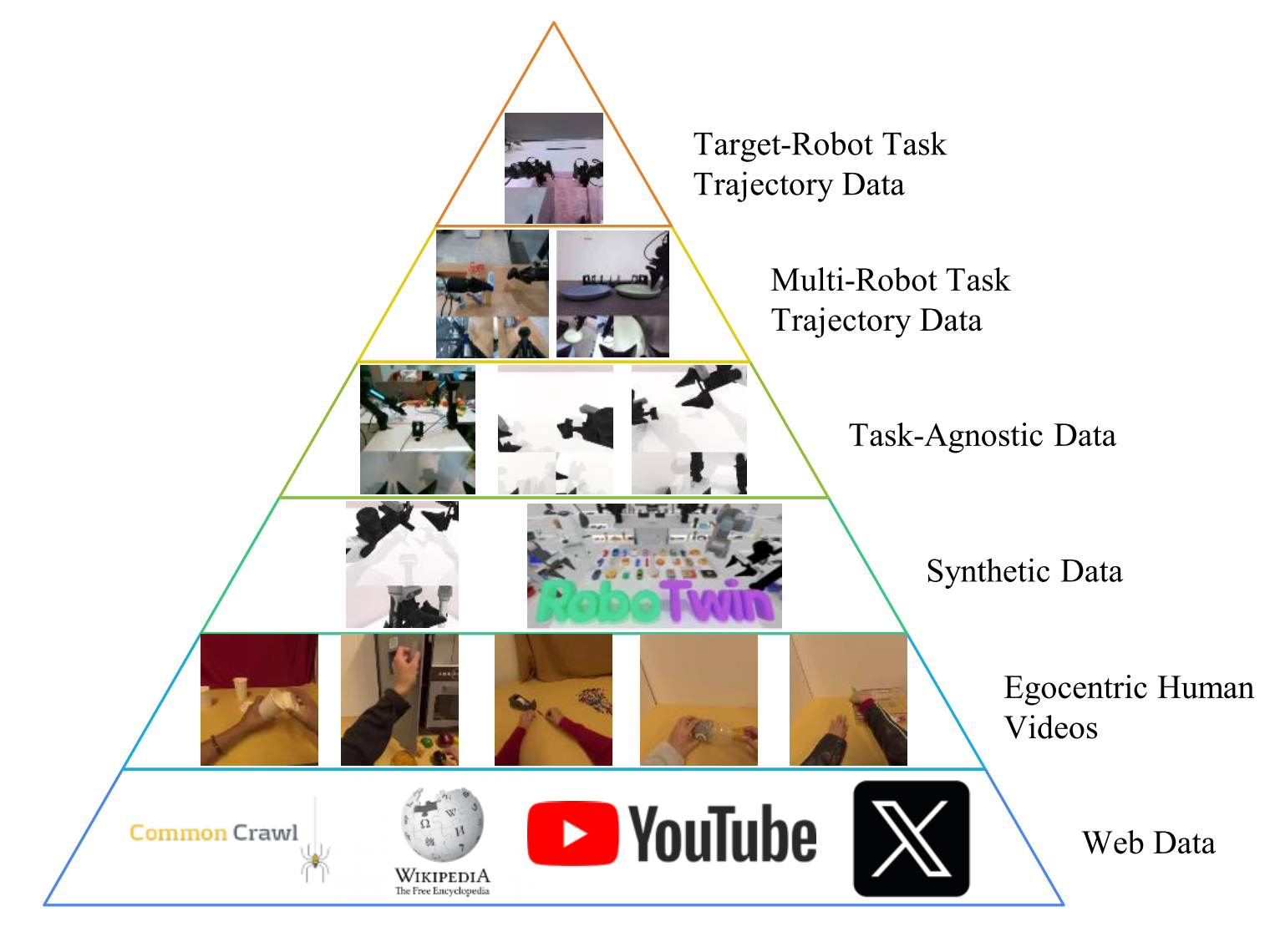
Figure 3: The Embodied Data Pyramid. Six-level data hierarchy from web data (Level 1) to target-robot demonstrations (Level 6), progressively increasing in task relevance and quality.
Three-Stage Training Recipe
1
Stage 1 (VGM Training)
Trains the VGM with embodied data.
→
2
Stage 2 (Motus Pretraining)
Pretrains the Motus model with latent actions.
→
3
Stage 3 (Motus SFT)
Fine-tunes the Motus model on target-robot trajectories.
| Stage | Data | Training |
|---|---|---|
| Pretrained Foundation Models | Level 1: Web Data | VGM and VLM |
| Stage 1 (VGM Training) | Level 2: Egocentric Human Videos Level 3: Synthetic Data Level 5: Multi-Robot Task Trajectory |
Only VGM |
| Stage 2 (Motus Pretraining) | Level 2: Egocentric Human Videos Level 3: Synthetic Data Level 4: Task-agnostic Data Level 5: Multi-Robot Task Trajectory |
Motus (all 3 experts, with latent actions) |
| Stage 3 (Motus SFT) | Level 6: Target-Robot Task Trajectory | Motus (all 3 experts, with actions) |